- Down the rabbit hole
- Posts
- IA : elle voit, elle lit, elle parle... mais comprend-elle vraiment ?
IA : elle voit, elle lit, elle parle... mais comprend-elle vraiment ?
Peut-on vraiment parler de cognition ou de raisonnement lorsqu’on parle d’IA ? Deux articles de recherche récents, l’un sur la perception spatiale, l’autre sur la complexité du raisonnement, éclairent cette question sous deux angles complémentaires.Voici ce qu’on peut en retenir.
J Bulle
10th juin 2025
1. Comprendre l’espace sans corps : mission impossible ?
Dans leur article Does spatial cognition emerge in frontier models?, les chercheurs d’Apple posent une question simple :
Une IA peut-elle comprendre l’espace sans en faire l’expérience physique ?
Chez les êtres vivants, la cognition spatiale repose sur l’intégration sensorielle : voir, entendre, toucher, lire l’environnement. C’est cette interaction constante avec le monde qui permet de construire une représentation cohérente de l’espace.
Les modèles d’IA actuels, eux, traitent chaque modalité séparément — vision, texte, audio — sans lien direct avec un environnement. Cette architecture désincarnée va à l’encontre du fonctionnement cognitif tel qu’on l’observe dans la nature.
D’où la question centrale :
La cognition spatiale peut-elle émerger sans perception unifiée ni interaction physique avec un monde réel ou simulé ?
2. Le benchmark SPACE : une mise à l’épreuve concrète
Pour tester cette hypothèse, Apple a conçu un benchmark nommé SPACE, inspiré de plusieurs décennies de psychologie cognitive.
Ce cadre évalue deux dimensions :
À grande échelle : navigation dans un environnement global (estimer des distances, dessiner une carte, retrouver un chemin, découvrir un raccourci).
À petite échelle : perception et manipulation mentale d’objets (rotation, mémoire visuo-spatiale, changement de perspective).
Les tâches sont proposées en version textuelle et visuelle, permettant d’évaluer aussi bien des LLMs que des modèles multimodaux.
3. Résultat : des IA perdues dans l’espace
Les modèles évalués (GPT-4o, Claude 3.5...) échouent largement. Leurs scores sont inférieurs à 50 % des performances humaines, et parfois proches du hasard.
Même sur des environnements simples (maison virtuelle), ils peinent à estimer des distances ou à retracer un parcours.
Les tâches considérées comme "élémentaires" chez les humains restent, pour l’IA, hors de portée.
4. Une intelligence différente… ou incomplète ?
Ce décalage interroge. Aucun système biologique ne combine des performances élevées en langage avec de telles lacunes en cognition spatiale.
Les auteurs en tirent deux hypothèses :
L’IA suit une trajectoire différente de l’intelligence humaine.
L’absence d’incarnation freine son développement cognitif.
Ces conclusions rejoignent les positions de Yann LeCun, qui plaide pour des IA autonomes, capables d’apprendre par interaction avec un environnement, et non à partir de texte seul. Il parle de “World Model”
5. Les limites du raisonnement, vues de l’intérieur
Deuxième article : The Illusion of Thinking (juin 2025). Les chercheurs d’Apple s’attaquent à une autre question fondamentale : les IA raisonnent-elles vraiment?
Aujourd’hui, les évaluations se concentrent sur la bonne réponse, rarement sur la manière dont elle est obtenue.
Les auteurs inversent la logique. Ils analysent non pas les résultats finaux, mais les étapes du raisonnement, dans un environnement de puzzles contrôlés à complexité croissante.
6. L’effondrement des modèles à haute complexité
Et les résultats sont frappants. Trois constats :
Jusqu’à un certain seuil, les modèles progressent.
Au-delà, leurs performances s’effondrent.
Leur effort de raisonnement diminue à mesure que la complexité augmente.
Les Large Reasoning Models (LRMs) produisent des raisonnements détaillés… jusqu’au point de rupture.
Et ce, même avec un budget de calcul (“tokens”) suffisant.
Trois régimes sont observés :
Problèmes simples : les LLMs standards font parfois mieux.
Problèmes intermédiaires : les LRMs ont un avantage.
Problèmes complexes : tout le monde s’effondre.
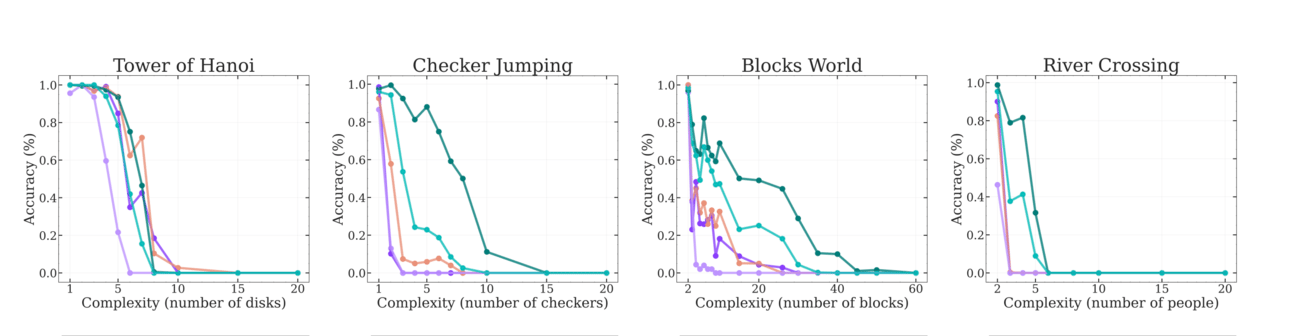
Evolution des performances des modèles IA sur les différents puzzle en fonction de la complexité. A partir d’un seuil : tous les modèles s’effondrent.
7. Quand donner la solution ne suffit pas
Même en fournissant la solution à certains puzzles, les modèles échouent à les reproduire dès que la structure devient trop complexe.
Cela suggère un déficit de compréhension réelle :
Ils manipulent des séquences de texte, mais ne comprennent pas les règles qui les sous-tendent.
Autre observation : leurs performances varient fortement selon le type de puzzle. Claude 3.7, par exemple, réussit bien les tours de Hanoï, mais échoue sur la traversée de la rivière.
Raison probable : les tours de Hanoï sont surreprésentés dans les jeux d’entraînement.
Ce biais renforce une idée simple :
Les modèles ne résolvent pas un problème parce qu’ils en comprennent les règles universelles, mais parce qu’ils en reconnaissent une forme déjà rencontrée.
8. Penser, ou rejouer ?
L’article ne nie pas les progrès des modèles IA. Il reconnaît leur efficacité sur certaines tâches, notamment lorsqu’elles s’appuient sur de vastes bases de connaissances textuelles.
Mais il met en garde contre une confusion courante :
Une bonne réponse n’implique pas une bonne compréhension.
Ce que nous appelons "raisonnement" chez ces modèles repose souvent sur la reproduction de formes vues ailleurs, plus que sur une capacité à abstraire ou recomposer.
9. Deux angles d’attaque, une même conclusion
Les deux articles aboutissent à un constat commun :
Nous sommes encore loin d’une intelligence générale.
Mais c’est justement en identifiant les angles morts de ces systèmes — qu’ils soient spatiaux ou logiques — que l’on pourra, demain, construire des IA capables de raisonner autrement.